What is FaceSwap ?

FaceSwap is a technology used for taking one face and swapping it with another in an image or video. What makes this news ? All the tools are available for anyone to use now!
its an interesting topic and its pretty current, I found the images of Nic Cage everywhere absolutely amazing, especially the Indianna Jones video, that was fantastic. Take a look at the video below!
I love the technology and the way its so accessible, unfortunately that comes with the bad part of it too, that people are using this to put people into situations they were never in.
What I’m trying to accomplish and what I want to share
So with the bad people doing bad things, what am I trying to do ?
I want to see how easy it is for a person like me to grab the required tools, and with very little understanding of the underlying technologies and how they work, see what I can accomplish at what to me, feels like the cutting edge of ML (Machine Learning).
Getting setup
The tools

![]()

The toolset runs on Python and uses OpenCV and TensorFlow on a GPU, this is pretty standard for this area from what I understand.
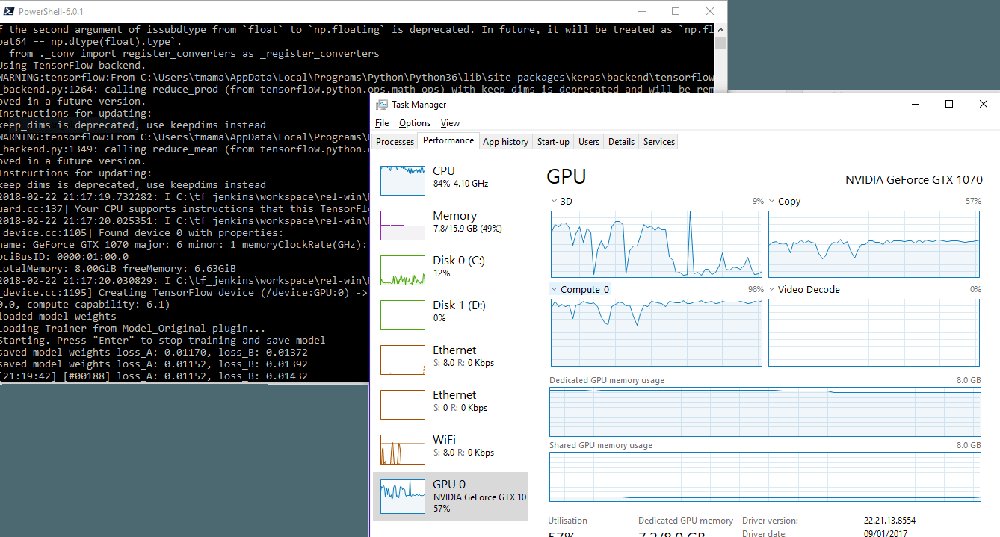
So I grabbed the source code, Python, OpenCV, TensorFlow and then proceeded to have ultimate pain on my windows box.
After fighting the requirements and massive Nvidia downloads of many different drivers. I actually upgraded the requirements for the DeepFace source code to a new version of TensorFlow, which then entailed using newer versions of CUDA and cuDNN and then the magic happened.
Faces!
Some of the libraries used are fascinating, to have the images setup the way you need, they actually understand that in all likelihood you’re not going to have a homogeneous image set of faces ready to use and provide a first step, which takes all the faces out of the photos you have, even doing some simple rotations to align them. I will definitely be using this feature in future.
Once I had my two face sets from an image search on my Google Photo’s by Name, I pulled the faces out and cleaned out the out directories of the additional people who appeared in the photos.
This took about an hour of manual labour, but there is now a very freaky collection of 300+ photos of me and my wife in single folders. (The actual recommendation is about 3000 photos, so I’m well under, this might bite me later)
I am imagining doing this process for multiple friends one day so I can put them in places they’ve never been and see if I can freak them out. That is probably a LOT of effort for a very minimal payoff.
Do the face magic
Now that we have training data, we actually need to train a model that will encode the logic for doing this transformation from one face to another, my understanding is that there are libraries logic for mapping the features of a face and with enough data the mapping from the one face to the other face will become seamless. This involves a lot of processing and trial and error to build a model that can do this in a repeatable fashion over and over.
The training step runs for a very long time and the longer you run it the better a result you get, thankfully this isn’t a one off process and you can pick up your training to make the resultant image better quite easily.
Make me images
The process of making images is quite straight forward of providing a source image, this then gets taken along with the model and the face mapping magic goes on, on your GPU and you get a new image outputted with the faces changed.
After a few minutes of processing, my data loss went down to 0.055 and my images looked like a child had cut a copy of the one face out and stuck inside the other!

You can see above how the alignment is actually amazing, but unfortunately without the face shapes being similar that effect is not believable at all. Even more so when we move to video.
Make me videos
Interestingly the process of creating a video is the same as with images, though its batch processing of the single frames which you then recombine back into a video.
Where to from here ?
Streamline
The technology is amazing and the work that has been put in is awesome, but there is a lot of manual tinkering to get to where you want to be, so automating this would be amazing.
I had a few ideas.
Face Classification from Source Images
This whole process could be automated, you take your whole image set, and let DeepFace automated the pulling of faces (which is already does), but then it takes those faces and matches them with each other to work out which are the same peoples (much like Google does using TensorFlow on Google Photos)
Automated model generation
Once we have our people classified, we could have a process to take all the images fed in and do all the combinations of models for those people.
Only replace the person for the model.
Since we can identify individuals now, you could actually only replace the face of the person who matches the model on a face match. This was a bit unfortunate from my experience that everyone gets treated to the model fitting.
Video Processing
Being able to process videos directly could be a boon for the software.
Audio
And finally since we’re doing the video now, we should extend this to do the audio as well. Imagine being able to change a person entirely in a video, including the way their voice sounded on your own home PC!
Adobe and Lyra both have products in testing to do just this, with one minute of audio!
The future is bright
And fake! or whatever you want it to be, depending on how you look at it.