Table of Contents
- Synopsis
- TLDR;
- The goal
- Nailing the pieces one by one
- What went wrong
- What went right
- What did I learn
- Where to from here
Synopsis

There is a particular pet hate I have, its voice notes. Often I am somewhere noisy, or busy with a zoom meeting and can’t listen, then even when I have the time to listen, I’m not aware of the content that is going to be announced out around me.
In my mind, the call to action on a text message is immediate, I see the message, often with a preview in the notification, respond and move on.
However, with voice notes you have to find the opportunity to listen to it, take it in and reply. I wished that there was some way of getting the text from the voice notes, without spending the time listening.
Thus started a fun journey with the potential ongoing advantage to me, of not having to listen to voice notes anymore.
At the time I made this, there were no services I knew of offering this feature. But Telegram has a subscription service which will now do this inline on voice notes for you. WhatsApp Speech to Text also seems to be coming. Well at least mine would still have the advantage of being free and private.
TLDR;
The Telegram bot is @shhhhhhhhhhhhhhhhh_bot click to start sending it voice notes.
I have a video, which covers most of the project, if you don’t feel like reading.
Most of the python code is available here, more for notes, not the full application.
Goal

I wanted to build some sort of service that would allow me to easily take my voice notes and get them transcribed into text, ideally it would always be online and ready to serve and it would not require me to buy or run any cloud infrastructure, or even having my home PC on and chugging electricity to serve some sort of massive GPU model for the couple voice notes I get in a day.
Nailing the pieces one by one

A way to access service from anywhere
I have always been fascinated by Telegrams bots and wanted to write something that I found useful using it. Without having any cloud infrastructure, I hoped I would be able to setup a bot and have it respond to voice message conversion requests in a timely fashion.
I figured I could run this on a Raspberry Pi, which I can leave on the whole time, I wouldn’t be too worried about its power consumption and it should have enough CPU and memory to receive messages and respond to them.
Using Telegrams, Botfather (great name btw), I created a bot very easily, no costs involved, anyone can do it. its really amazing that they offer this service for free. To make the bot do something, I used Python, a language that I have had a lot of fun with in recent times for personal projects, as it allows me to build things very quickly without getting in the way.
There is a python library for integrating with Telegram, python-telegram-bot its really easy to get up and running too. Their front page literally has all the code you would need to setup a “Hello World” bot
Speech to Text service
When I heard about Open AI Whisper, I thought this was great, an open source speech to text service which you could run locally. The idea was to somehow get the voice messages I received, transcribed to text and let me reply in my preferred fashion, text.
Georgi Gerganov is a magician and made a version of Whisper, whisper.cpp, which is small enough to run on a desktop PC without a GPU, or even Raspberry PI, check the github repo here, this made me think that maybe a Raspberry Pi would be able to even handle the load. It could be online always as I wasn’t really worried about the power consumption of it.
I tried the smallest available dataset and since it was running well, but a little bad at conversions, I switched to the small model, which still ran great and had much better results.
Linking it together

At first thought I was looking at integrating the Telegram bot directly with the code for whisper.cpp, but given the time I wanted to invest, there was an example that would accept a wav file and convert it to text. The idea was then to have the Telegram bot accept messages with attachments and then convert those to .wav, which the example code could parse and convert and get the end result back into my Python Telegram Bot and send the text conversion back.
Python once again to the rescue has some great tooling for executing shell scripts using Popen which allows you to run commands. You really want to be careful with things like this, they’re a massive security hole. Since I’m not accepting text directly, I don’t have to worry about the command injection coming in, so much as bad payloads which somehow blow up FFMpeg and allow arbitrary command execution. As they say the first task is knowing about the problem…
If there are any errors during this process, we’ll tell the user we couldn’t convert the audio to text.
FFMpeg is an amazing CLI tool that can do almost anything to do with video and audio. I’ve used it on a previous project to generate a scrolling video of a long screenshot, with very little code, even managed to get it to synch the scroll time to the audio sample… on the CLI! I was even able to get it to extract the audio from smaller video files and do speech to text on that.
A simple command like this can extract the audio from the given input file to a suitable wav file
ffmpeg -i input.mp3 -acodec pcm_s16le -ac 1 -ar 16000 output.wav
-i for input -acodec for the output audio codec, set to PCM -ac for audio channels, set to 1 here -ar for audio rate, set to 16khz here
I had a small concern about the SD card wear and tear, so I setup a ram disk to download and decompress the samples on, startup mounted ramdisk in linux. You can learn more about that here
What went wrong

Surprisingly, the approach worked really well, I had a few troubles working out the python code for accepting and processing attachments.
The key learnings were
# Setup the handler to accept attachments at startup
application.add_handler(MessageHandler(filters. ATTACHMENT, handle_message))
# In your handler
async def handle_message(update, context):
# Get the file
file = await context.bot.get_file(update.message.effective_attachment.file_id)
# Save the file to disk for processing
source_file = await file.download_to_drive(custom_path="/mnt/ramdisk/"+fileid)
# Do cool stuff
Another one was thinking that my Pi wouldn’t restart and I could just run the python application. It was pretty amazing how often I would bump the poor ‘server’ and it needed me to remote in and start the application again. systemd to the rescue.
I setup a service in /etc/systemd/system/shhh.service, which is set to autostart on system startup and restart on any failures. One of the interesting things in here is setting up your environment variables in a .conf file, which can hold some of the variables I don’t want in my code, like the Bot API key and my Telegram Chat ID, to see processing messages.
/etc/systemd/system/shhh.service
[Unit]
Description=Shhh Telegram Service
Documentation=...
[Service]
Type=simple
EnvironmentFile=/etc/systemd/system/shhh.conf
User=shhh
Group=users
TimeoutStartSec=0
Restart=on-failure
RestartSec=30s
#ExecStartPre=
ExecStart=/projects/shhh/shhh.sh
SyslogIdentifier=Shhh
#ExecStop=
[Install]
WantedBy=multi-user.target
/etc/systemd/system/shhh.conf
SHHH_API_KEY=1111111111:AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
SHHH_MY_CHAT_ID=11111112
What went right

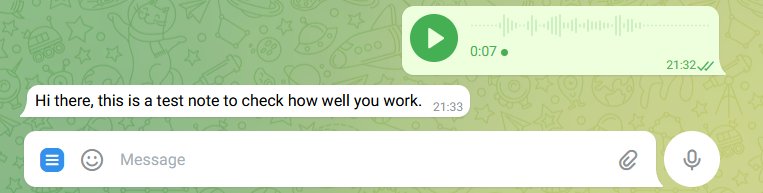
The bot is up and running and it is always available for me, and anyone else actually, to convert voice notes and videos audio to text. The speech to text conversion is usually great, allowing me to reply to a voice note without ever listening to it. I only use it once a week, but I keep simple stats on calls to the service
For the workflow its pretty good, without being able to integrate into the messaging app directly. Most voice notes arrive in WhatsApp and I can long click them and share them to Shhh bot which will start the Speech to Text and return the result to me in under a minute.
What did I learn

Telegram Bots
I really enjoyed learning how to use Telegram and how flexible it is to setup small services. Learn more here
Whisper
The AI type tooling is getting really good and can run on relatively inexpensive hardware given the right versions of models and some more optimised implementations. Read more here
FFMpeg
Anytime I have some media processing to do now, I find myself quite happy to jump into a command line and start hacking with FFMpeg Get started here
Linux
Manually starting services is no good, from now on I’ll happily put a systemd service in place, I really liked the config file for environment variables. Give it a go here
Where to from here
Using a Telegram bot for automation of some form was a great learning experience for me and I’m very open to using this approach in the future for dynamic interactions and not having to host a web-server or other online resource to do simple tasks. It would be amazing to host my own Stable Diffusion model for generating images on my own private compute, but the Pi wouldn’t be quite powerful enough for that from my experiences so far.
There’s a really interesting project called Piper, which actually does the opposite of Whisper and converts text to speech, I haven’t see anything this good running on a Pi before. That will be a project for another time though.